今日、日本時間5時すぎに「NVIDIA GTC 基調講演」がオンラインで行われ、その中で今後のNVIDIAの注力製品群についても説明がありました。
基調講演の内容は以下から視聴できます。
今回、その講演の中で次期GPUコアモデル「Orin」についても少し触れられていたほか、午後6時ごろに次世代NVIDIA Jetsonモデル「Orin」シリーズの専用サイトやスペック情報が解放されました。
NVIDIA Jetsonシリーズは、Raspberry Piのようなシングルボードコンピュータ(SBC)であって、特にGPUまわりの演算性能が強化された計算モジュールになります。
ロボットや精密機械などの組み込みコンピュータとして使われているほか、開発者キットをそのまま使ってPCと同じようにAIなどの機械学習やプログラミングに役立てることができます。
今回発表されたのは、すでにロードマップで示されていた下記の2製品です。
- Jetson Orin NX (Jetson Xavier NXの後継)
- Jetson AGX Orin (Jetson AGX Xavierの後継)
ロードマップや今後提供されるJetson向けソフトウェアパッケージ「JetPack 5.0」については別の投稿で触れています。
本エントリーでは、Jetson Orin NXについて触れてみたいと思います。
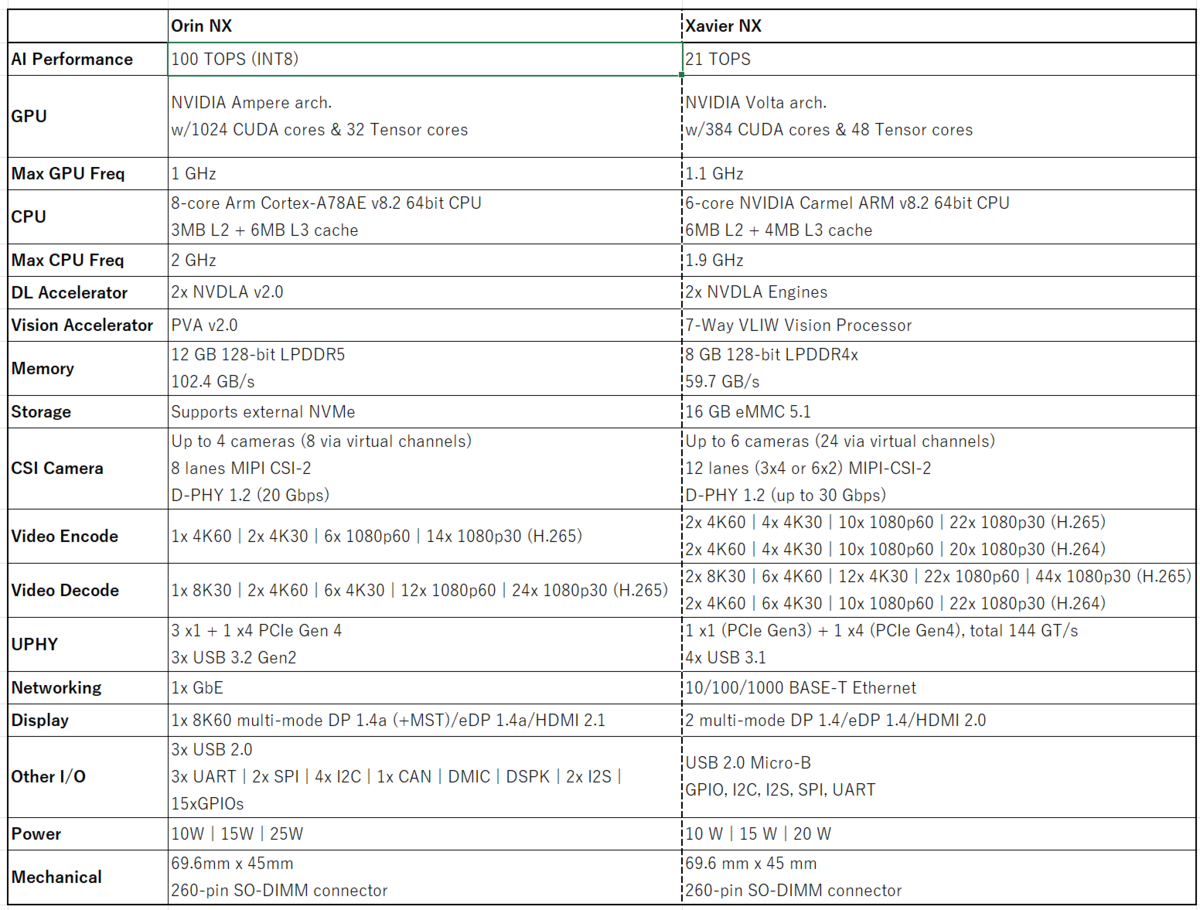
まず、基本性能の比較を下記の表にまとめました。
| Orin NX | Xavier NX | |
| AI Performance | 100 TOPS (INT8) | 21 TOPS |
| GPU | NVIDIA Ampere arch. w/1024 CUDA cores & 32 Tensor cores |
NVIDIA Volta arch. w/384 CUDA cores & 48 Tensor cores |
| Max GPU Freq | 1 GHz | 1.1 GHz |
| CPU | 8-core Arm Cortex-A78AE v8.2 64bit CPU 3MB L2 + 6MB L3 cache |
6-core NVIDIA Carmel ARM v8.2 64bit CPU 6MB L2 + 4MB L3 cache |
| Max CPU Freq | 2 GHz | 1.9 GHz |
| DL Accelerator | 2x NVDLA v2.0 | 2x NVDLA Engines |
| Vision Accelerator | PVA v2.0 | 7-Way VLIW Vision Processor |
| Memory | 12 GB 128-bit LPDDR5 102.4 GB/s |
8 GB 128-bit LPDDR4x 59.7 GB/s |
| Storage | Supports external NVMe | 16 GB eMMC 5.1 |
| CSI Camera | Up to 4 cameras (8 via virtual channels) 8 lanes MIPI CSI-2 D-PHY 1.2 (20 Gbps) |
Up to 6 cameras (24 via virtual channels) 12 lanes (3x4 or 6x2) MIPI-CSI-2 D-PHY 1.2 (up to 30 Gbps) |
| Video Encode | 1x 4K60 | 2x 4K30 | 6x 1080p60 | 14x 1080p30 (H.265) | 2x 4K60 | 4x 4K30 | 10x 1080p60 | 22x 1080p30 (H.265) 2x 4K60 | 4x 4K30 | 10x 1080p60 | 20x 1080p30 (H.264) |
| Video Decode | 1x 8K30 | 2x 4K60 | 6x 4K30 | 12x 1080p60 | 24x 1080p30 (H.265) | 2x 8K30 | 6x 4K60 | 12x 4K30 | 22x 1080p60 | 44x 1080p30 (H.265) 2x 4K60 | 6x 4K30 | 10x 1080p60 | 22x 1080p30 (H.264) |
| UPHY | 3 x1 + 1 x4 PCIe Gen 4 3x USB 3.2 Gen2 |
1 x1 (PCIe Gen3) + 1 x4 (PCIe Gen4), total 144 GT/s 4x USB 3.1 |
| Networking | 1x GbE | 10/100/1000 BASE-T Ethernet |
| Display | 1x 8K60 multi-mode DP 1.4a (+MST)/eDP 1.4a/HDMI 2.1 | 2 multi-mode DP 1.4/eDP 1.4/HDMI 2.0 |
| Other I/O | 3x USB 2.0 3x UART | 2x SPI | 4x I2C | 1x CAN | DMIC | DSPK | 2x I2S | 15xGPIOs |
USB 2.0 Micro-B GPIO, I2C, I2S, SPI, UART |
| Power | 10W | 15W | 25W | 10 W | 15 W | 20 W |
| Mechanical | 69.6mm x 45mm 260-pin SO-DIMM connector |
69.6 mm x 45 mm 260-pin SO-DIMM connector |
モジュールサイズは完全互換で、ピン数もサイズも一致しています。
そしてOrin NXのCUDAコア数はXavier NXの2倍以上!AIパフォーマンスは4倍以上!
画像処理に特化させてどんどん学習データを集めていく用途に向いていそうな気がします。
ただ、MIPI CSI接続が可能なインタフェースの数が、Orinは少なく設定されているため、たとえば6台のMIPI CSIカメラを接続して計算するという使い方はOrinではできなくなっています。
また、ハードウェアエンコーダやデコーダの性能が半分に低下しており、Xavier NXでは2ストリーム同時に処理できていた4K60p映像のH.265エンコードも、Orin NXでは1ストリームまでしか対応できないようです。
Xavier NXではH.264よりもH.265の方が処理性能が高いことから、たとえH.264であったとしてもOrin NXのハードウェアエンコーダの性能にほとんど差異はなく、同様にVP8/VP9に関してはこれよりも低いと言えそうです。AV1が1ストリーム4K60pでエンコードできる可能性はワンチャンありそうですが。
と考えると、カメラの数やエンコード性能よりも、エッジコンピューティング用途など末端の計算デバイスとしての計算能力の強化をはかったモデルと考えるのが妥当でしょうか?
従来のJetson Xavier NXやNanoが各種データの取得や簡単な計算処理までを担っていたのに対して、Orinシリーズでは機械学習や推論などのさらに高度で高速な計算を要する処理にも対応させようと意図しているのかもしれません。
先述のとおり、CUDAコア数が倍以上に増えているほか、CPUもコア数が2つ増え、メモリ帯域幅も2倍近く高速化しています。まさにコンピュータとしてゴリゴリに並列計算させるのに適したアーキテクチャになっているように見えます。
ストレージに関しては、Orinシリーズは内蔵ストレージ(eMMC)を持たず外部ストレージ(NVMe SSDなど)へのシステム書込みのみに対応しているようです。
最近、NVIDIA SDK ManagerがXavierシリーズでSDカードやeMMC以外の、NVMeやUSBストレージにシステムをフラッシュ(書き込み)できるように対応(JetPack 4.6~)しましたが、OrinシリーズではそもそもNVMeがないとシステムの書き込みができないということになるのでしょうか。
最後にOrin NXシリーズの出荷時期についてですが、ウェブサイトでは1年後のこの時期(Q4 2022)にモジュール版(製品組み込み版)を提供開始すると記載されています。開発者キットについては来年春頃(Q1 2022)になりそうです。
ただし半導体不足の昨今ですので、それが解消されない限りは入手しづらい状況にあるかもしれません。
また、PCIeまわりのインタフェースが強化されたことや、NVMe SSDが事実上必須であるという状況を見ても、現行のXavier NXとはまた違ったキャリアボードになりそうな予感がしています。もしかするとTX2のようなクソデカキャリアボードになるかもしれません。
Jetson Nanoシリーズの後継については、2023年にNano Nextシリーズが予定されているので、新しい情報が出てくるまであと1年くらいは待つ必要がありそうです。
次回は AGX Orin について同様に比較してみます。
▼以下の記事を追加しました!
はやく試してみたいですね!(`・ω・´)